
The term “scalable” is frequently mentioned when discussing cloud services. The statement that “cloud services are scalable” is undoubtedly accurate. They facilitate scaling and frequently function out of the box. However, there are times when we need to take charge and specify precisely how that scaling should operate. When it came to scaling our ECS cluster-based microservices, this has been the case for our team. Please allow me to describe our experience. Summary of the product To put it succinctly, we are a small group of three developers working on a data platform, sharing duties in the backend, frontend, and operations departments. It doesn’t always get a lot of visitors. Instead, clients who upload a large number of files often experience traffic spikes. From a business standpoint, our goal is to complete these tasks as quickly as possible so that users can begin working with the newly uploaded data. Our system is message-driven and asynchronous, with many different microservices sharing responsibilities. We use MSK (AWS-managed Kafka) as our durable message log, RDS as our main relational database, and OpenSearch (AWS-managed Elasticsearch) as the primary engine for handling data reads in our web UIs.
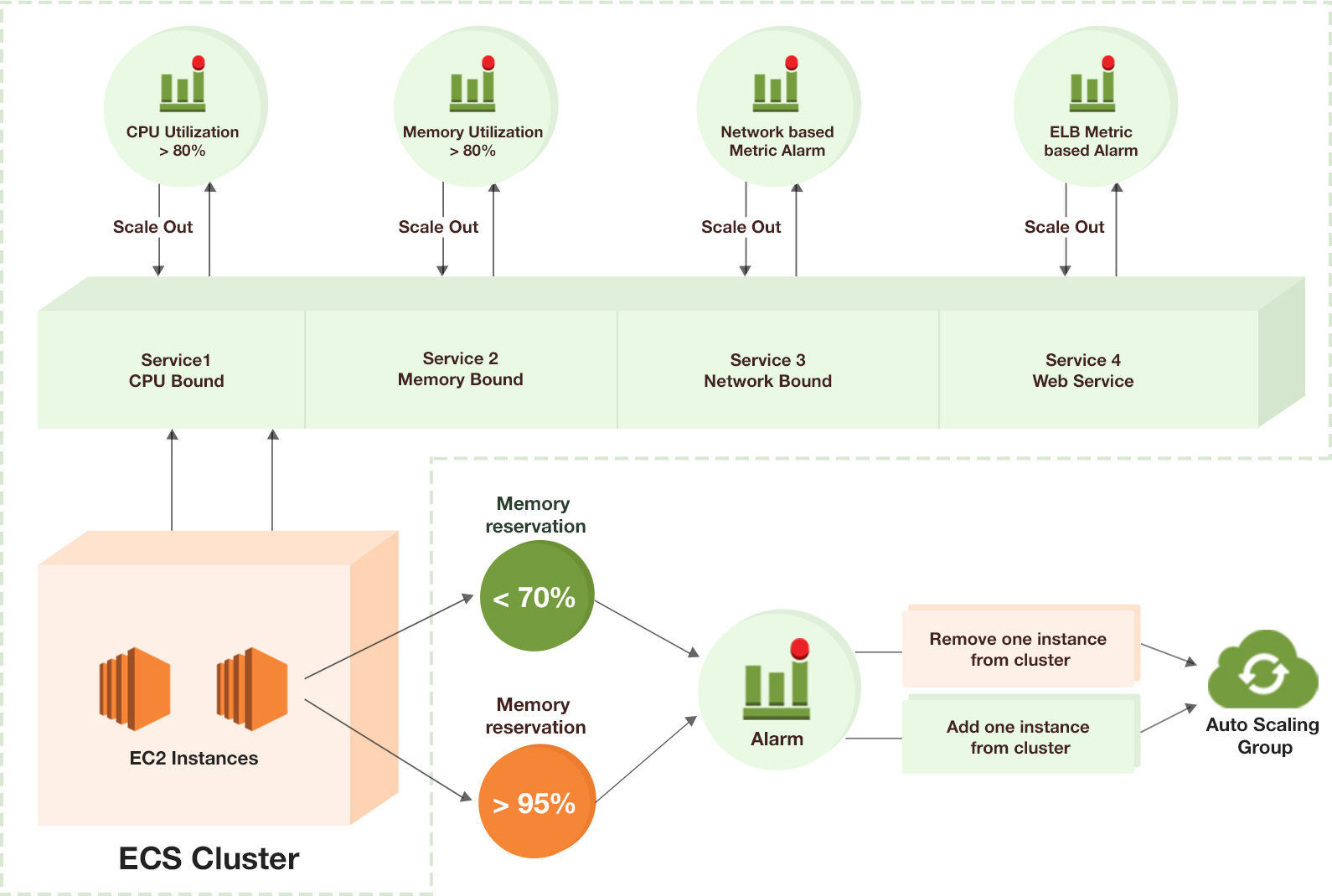
Initial configuration and issues At first, all our services ran in a single ECS cluster, using the same autoscaling policy. The service would scale out when memory usage exceeded 80 percent. Scaling was based on memory usage. It would scale back in when it fell below 20%. It was a default that was used in all of our client’s clusters that used other products. It became abundantly clear that our setup was insufficient as we added more customers and noticed increased traffic spikes. Our microservices didn’t really have a problem with memory usage, as the metrics demonstrated. We were instead encountering CPU contention. A single container task could consume all of an EC2 instance’s resources, particularly during traffic peaks because none of our services had hard limits on memory or CPU usage. As a result, restart-and-retry loops were occurring when other services failed to respond to automated AWS health checks. We tried to get ahead of a traffic peak by manually adding more EC2 instances and tasks to the cluster when we knew one was coming. Although it was a quick fix, it also meant more work and stress. This strategy was helpful at times, but it didn’t solve the main problems.
We continued to experience CPU contention, had no idea how many additional tasks we should spin up, and lacked the time to dynamically monitor the results. Determine factors for scaling We finally had time to address our autoscaling issues at some point. Finding the right scaling factors for your deployment is the first step in finding solutions to these problems. Checking your metrics and comprehending your code are the best ways to accomplish this. Since we were already aware that the CPU was a bottleneck, we used that as our first scaling factor. The second one was event stream processing lag, which is common in message-driven systems. This indicated that the consumer group lags in several fundamental Kafka topics in our instance. Additionally, we came to the realization that some of our services primarily deal with HTTP requests that are merely database reads and writes. These services don’t need as many resources as others, like image processing, which uses a lot of CPU power and is more dependent on consumer group lag.
We made the decision to divide these two groups into two separate ECS clusters, one for CPU-intensive services and the other for light ones. We are able to monitor each cluster independently and implement various autoscaling strategies as a result of this. Limit the amount of resources. By imposing hard resource limits on ECS tasks, one can alleviate CPU contention issues. However, there are important trade-offs and consequences associated with this. First, resources are wasted if a task is not completed. Second, it’s hard to figure out good hard limits because you have to know or even measure how much CPU and memory a service needs for different workloads. Instead, we decided to limit our ECS container tasks with soft limits. What’s the difference, then? Tasks with the same resource ratio, like 0.5 vCPU, can share those resources as needed with soft limits. For instance, if two tasks each have a soft limit of 0.5 vCPU and one is idle while the other is working on CPU-intensive tasks, the busy task can temporarily use the idle task’s unused 0.5 vCPU. There is no competition or contention when the idle task resumes activity; it simply gets the CPU it requires. It uses resources more effectively than hard limits do and doesn’t need as much precision or strict configuration.
Cluster pattern We divided our services into two ECS clusters, as previously mentioned. Services on the “regular” cluster primarily manage HTTP traffic. Based on CPU usage, these services scale. In practice, this cluster rarely generates more EC2 instances than the initial minimum. A few core HTTP services, such as those handling file uploads and parsing, facilitate the most essential business processes during heavy workloads. These services scale out with a few additional instances, but typically that is all they do. Our RDS instance, which is shared across microservices, is the platform on which most of these services perform relational database operations. A distinct RDS schema belongs to each service. Since each task maintains its own connection pool, we occasionally reach the database connection limit during scale-out. We implemented an RDS Proxy into our environment to address this issue, which facilitates more effective connection distribution and management. However, there is a cost to this: a slight increase in latency.
A few core services that are essential to the performance of workloads still connect directly to RDS to compensate for this. Database traffic is handled by the proxy by services that aren’t as important or used as much. Since then, we haven’t had any connection issues. We would eventually vertically scale our RDS instance, examine the load, and possibly make use of RDS read replicas. Cluster computing Our CPU-intensive services are handled by the second cluster, which scales based on consumer group lag. Each service starts with a single running task by default. We are prepared to process some Kafka messages without having to scale out if the workload is small, and this is basically a standby mode. The scaling strategy used by this cluster is more aggressive than the standard one.
This means that services scale out in higher steps (depending on the service) from one task instance to five, then ten, and so on when lag is above a certain threshold for a certain amount of time. We can anticipate that messages will be distributed fairly evenly given that our Kafka topics do not employ any fine-grained partitioning strategy. Therefore, partition assignment during scaling is not a concern for us. As a result, the maximum number of task instances in our instance is limited to the number of partitions per topic, which is 30. The scale-down factor is straightforward: we return to a single task instance when consumer group lag reaches zero. Optimum tuning We conducted numerous tests with various configurations to observe how the platform responded in order to determine the appropriate scaling thresholds and step sizes.
It takes time and hands-on testing with real workloads; there is no real shortcut here. On our staging environment and later in production, we carried out load tests. It is essential to have effective monitoring in place at this point. CPU and memory utilization—both at the cluster and per service level—along with the number of EC2 and task instances, response times, and consumer group lag are some of our primary indicators of scaling effectiveness. Monitoring your single point of failure, such as databases, is also a good idea because they might see more load than your team usually does when the platform grows. In our case, we identified and optimized a number of SQL calls made by services that were consuming a lot of CPU on the shared RDS instance. In the end, we settled on a configuration that satisfied our needs. Our compute cluster was able to keep up with all of the asynchronous processing during heavy upload workloads, when large batches of files were sent to the platform. As a result, all of the results were available almost immediately after the uploads were completed. The characteristics of the workflow you’re trying to scale play a big role in fine-tuning. Because each project is unique, it is essential to have a thorough understanding of your system in the beginning.
Summary
The entire procedure, including load testing and fine-tuning, took more than a month. We gained a lot of knowledge about our services and ECS autoscaling. From a business standpoint, our improved overall platform performance had a direct impact on how our customers used our product. As developers, we also gained peace of mind because we no longer have to manually try to make changes or deal with traffic spikes. Identifying the appropriate scaling factors, which entail comprehending your workload, and fine-tuning the scaling parameters, are, in my opinion, the two most crucial steps in working on ECS autoscaling. There is no one-size-fits-all solution because every product is unique and there are some aspects that are difficult to generalize. You will eventually arrive at the correct location if you take your time and rely on the results of your metrics and load tests.

